本文内容均是根据权威材料,结合个人观点撰写的原创内容,辛苦各位看官支持。
MIT天才博士,清华学霸肖光烜官宣,正式加盟ThinkingMachines,下一步主攻大模型预训练
这两天AI圈最大的瓜,莫过于MIT博士肖光烜官宣加盟ThinkingMachines(简称TML)。
这位顶着清华双学位、MIT光环的学霸,一出手就瞄准了大模型最头疼的效率问题显存不够用、推理慢得像蜗牛、长文本处理卡壳。
现在搞大模型的谁家不被这些问题折磨?肖光烜的加入,怕是要给行业带来点不一样的东西。

从清华园到MIT实验室,学霸的高效计算修炼之路
2019年,肖光烜在清华拿了综合优秀奖学金。
别以为这奖好拿,清华园里藏龙卧虎,能脱颖而出的都是真学霸。
第二年更猛,全国大学生数学建模竞赛一等奖+国家奖学金,双buff叠满。
2021年又摘得清华"未来学者"奖学金,妥妥的学神级人物。
他读的是计算机和金融双学位,本来想,这俩专业八竿子打不着,后来发现跨界反而成了优势。
金融里的资源调配思维,被他用到算法优化上,居然挺好用。
比如算模型参数时,怎么用最少的资源办最多的事,金融课上学的那套逻辑直接就用上了。
在清华打好基础后,肖光烜把目光投向了更远的地方斯坦福大学。
2020到2021年,他在斯坦福计算机系当访问学生。
这里的深度学习研究已经玩出花了,什么高效系统、模型压缩,都是前沿中的前沿。

这段经历像给他打开了新世界的大门,心里大概就有了方向,搞高效深度学习系统。
2022年,肖光烜进入MIT读博,导师是韩松教授。
韩松是谁?高效计算领域的大牛,MobileNet就是他团队搞出来的。
跟着这样的导师,研究方向自然更明确了,深度学习的高效算法与系统。
从2022年9月到2026年1月,他还兼任MITEECS全职研究助理,等于边学边干,理论实践两手抓。
光有理论不行,还得落地。
2023年,肖光烜去Meta实习。
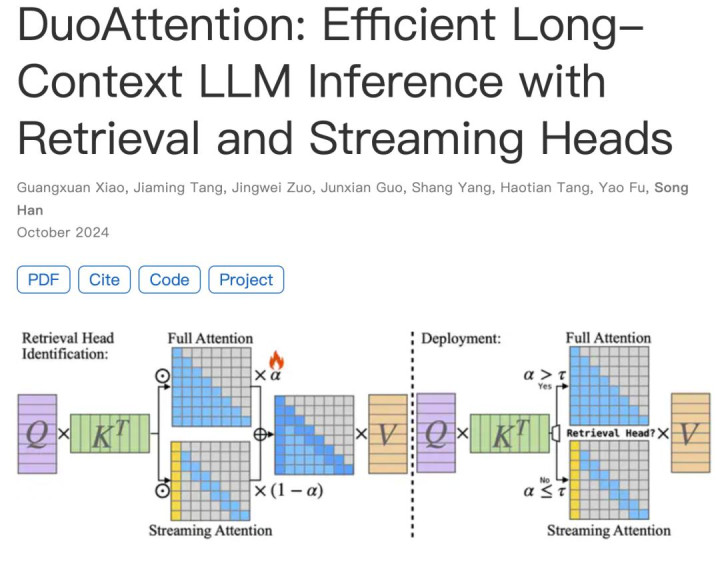
当时大模型上下文处理已经是老大难,他就研究流式语言模型的高效注意力机制,成果直接发在了arxiv上。
转过年来,2024年2到5月,他又去了英伟达,这次更猛,提出DuoAttention机制,直接把长上下文大模型的推理速度提上去了。
能在Meta和英伟达这两大AI巨头实习,还都拿出硬核成果,这实力确实没话说。

从实验室到产业,破解大模型"效率密码"的野心
肖光烜最厉害的,是他搞出了一套完整的高效模型技术框架。
先说说SmoothQuant,这玩意儿解决了工业界一个老大难问题。
以前模型量化时,激活值老是忽高忽低,像坐过山车,根本没法稳定量化。
他想出个数学等价变换的招,把激活值的波动给捋平了。
这下好了,十亿级模型直接实现W8A8无损量化,不用重新训练,显存占用少了,推理还变快了。
企业一看,这不就是白捡的便宜?
还有StreamingLLM,这技术更神。
他发现大模型注意力机制里有个"注意力汇点",就像人群里总有个核心人物,抓住它就能稳住上下文。
基于这个发现,他搞出常数内存流式推理,上下文长度从几千token一下扩展到百万级。
后来还延伸出StreamingVLM,连视频处理这种多模态任务都能搞定。
推理效率优化上,他更是玩出了组合拳。

DuoAttention搞混合注意力,解决KVCache存储难题,XAttention用反对角线评分,让预填充阶段加速,FlashMoBA定制CUDA内核,连小块架构GPU都能发挥最大性能。
这些技术放一起,就像给大模型装了个"超级引擎"。
如此看来,肖光烜这套技术体系,从算法创新到系统优化,一环扣一环,确实给下一代计算高效AGI打下了基础。
难怪TML要花大价钱挖他。
TML到底有啥魅力?
2025年Q1数据显示,他们技术员工平均年薪46.25万美元,比OpenAI、Anthropic这些同行都高。

更关键的是,这还是种子轮融资前的薪资水平,说明公司一开始就把人才放在首位。
肖光烜选择TML,显然不是只看钱。
他主攻的大模型预训练方向,正好能把自己的高效技术落地。
从实验室的理论创新,到产业界的规模化应用,这条路他走得很清晰。
现在大模型都在拼参数规模,却忽略了效率,他这步棋算是找准了痛点。

其实学术界和工业界的协同创新,肖光烜算是个典型例子。
基础研究做得深,应用落地跟得紧,人才流动起来,技术迭代自然快。
未来大模型要普惠,光靠堆算力不行,还得靠这种高效计算技术。
毕竟不是每家公司都能烧得起成百上千张GPU。
说到底,21世纪最贵的还是人才。

肖光烜从清华学霸到MIT博士,再到TML的技术骨干,他的经历本身就是一个信号,大模型行业的竞争,终究是人才和技术的竞争。
而高效化,或许就是大模型从"少数玩家游戏"走向普惠的关键一步。
大财配资,闻道资本配资,配资平台app提示:文章来自网络,不代表本站观点。



